Visualizing sketchy ad networks
Introduction
This post will be an attempt at visualizing some of the strategies used by attackers to make money on "sketchy" advertisements. I also cover some of the both static and dynamic methods they use to avoid detection. This is very much related to my previous post on a major attack on Swedish websites: New attack in progress (live). It is also related to an advanced fingerprinting script I'm currently analyzing: GitHub beneri/js-fingerprint-redirect (feel free to help and send a pull request).
The domains used in these attacks and networks are quickly changing. This makes it hard to understand how domains from different campaigns are interconnected. A long-term goal would be to run these scans continuously.
If you just want to check out the graphs you can view them here. Each node is a domain and each edge is a redirection (could be server-side or client-side). The weight on each edge is how many times that particular redirection happened. The red nodes mean that the domain is blocked by EasyList.
- log-100k-US-EAST-vpn.txt.gv.pdf
- log-200k-req-home-normal.gv.pdf
- log-240k-ukraine-vpn.txt.gv.pdf
- log-2k-philippines.txt.gv.pdf
- log-570k-sweden-novpn.gv.pdf
Small example
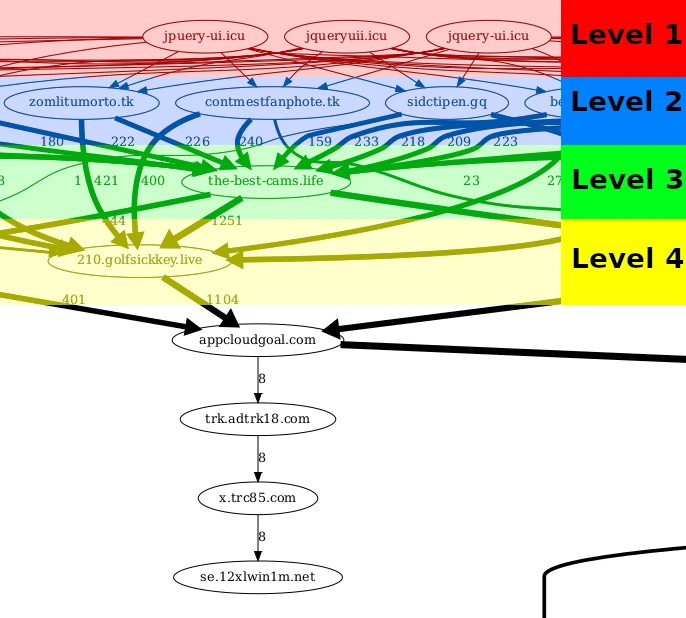
In this section, I want to focus on a small part of the graph and explain some of its structure before diving into the details. In the image above we see the very tip of the iceberg in the log-200k-req-home-normal.gv.pdf graph. The cool part here is that we can clearly see the first levels of the hierarchical structure.
Level 1. These domains are controlled by attackers and used to host JavaScript that is injected into victim websites. There can be multiple different ones but they do not change over time. They can be thought of as the hard-coded C&C server addresses in classic malware.
Level 2. The domains from level 1 will redirect users to the domain in level 2. However, the domain in level 2 can be updated frequently. In the case of the attack on Swedish web sites this domain is updated every 10 minutes.
Level 3. Here I'm less sure. I believe this is some type of "introducer" into the ad network. Probably not controlled by the attacker. It would be interesting to find some other website pointing to the-best-cams.life. This domain is very stable and I have not seen it change for over a month. It was registered back in June 2022. Note: Due to a bug/limitation in the methodology it looks like some requests are jumping directly from level 2 to level 4, this should not happen. This seems to happen because the redirects are sometimes cached by the browser.
Level 4. This is similar to level 2 in the sense that the domains here are constantly updated. In this case, the timings range from 10 minutes to 1440 minutes (24 hours). For example, below are the domains the-best-cams.life redirects to over time (scanned every minute).
Domain First seen Last seen Duration https://jewnoseya.live 2022-12-03 12:57 2022-12-03 13:09 12 minutes https://byebossweak.live 2022-12-03 13:10 2022-12-04 13:10 1440 minutes https://trylandvary.live 2022-12-04 13:11 2022-12-04 13:21 9 minutes https://leawantrim.live 2022-12-04 13:22 2022-12-04 13:51 30 minutes https://zipfacthow.live 2022-12-04 13:52 2022-12-04 14:54 61 minutes
The PornHIT Cluster
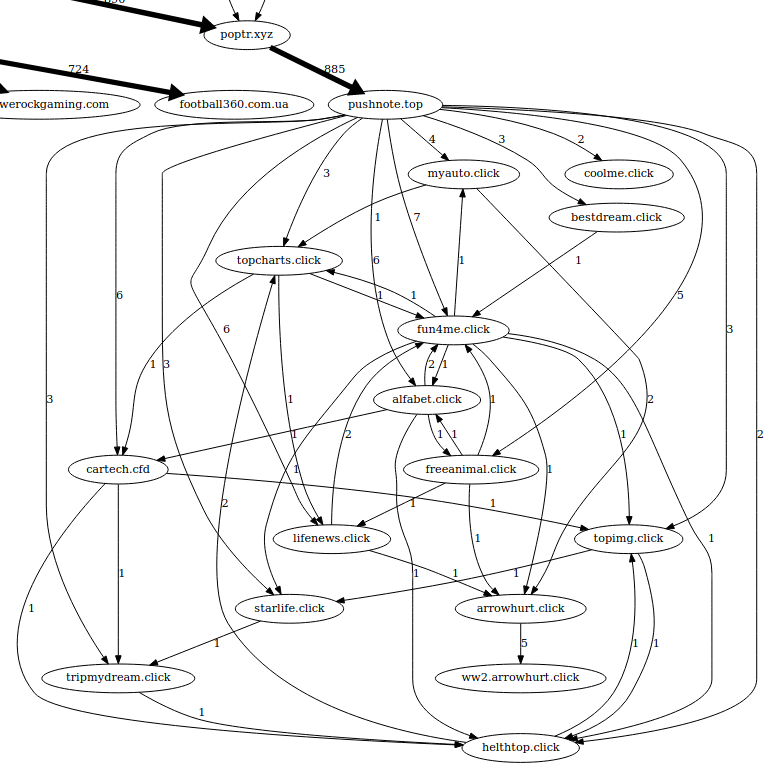
Another short example I wanted to showcase is the "PornHIT" cluster.
This was only found when I used the VPN server from Ukraine (log-240k-ukraine-vpn.txt.gv.pdf).
In this case, after about 8 redirections the user lands on pushnote.top.
This website is a type of
website notifications pop-up scam
that asks users to "Press allow to continue" and then if they do, starts sending advertisements.
The website then grabs another domain for a list of 13 domains (https://api-un.unative.com/p/d/getAll),
redirects the user to it, and repeats the same attack. Previously, if you visited any of these domains they would show a blurred image of a porn website.
Now it is just blank but if you check the source code you can still see the old title: <!-- <title>PornHIT</title>--> . Can also be found on the Wayback Machine.
The actual "Press allow to continue" only shows up if you go to the progress-bar.html file. E.g. pushnote.top/progress-bar.html?un=...
And this is just one cluster of many clusters worth investigating!
Random fun facts
Hiding the tracks
I noticed that google.com was redirecting to the Casino spam sitesmac-dak.ru and tanika-br.ru.
At first, I thought it might have been a mistake on my part but it turns out they are abusing an open-redirect vulnerability in Google.
This is not the first time attackers use this according to Sophos. Open-redirects have been discussed at length already, if you are interested there is a great video on the topic here: No Bounty for Open Redirects?! – ft. LiveOverflow.
They also use combine dereferer.me and Twitter's t.co URL shortening for redirects.
E.g. the following chain:
https://dereferer.me/?https%3A//t.co/4ynWxlLVbQ https://t.co/4ynWxlLVbQ casinoreviewers.comAnd since it is a Twitter link we can find the original account that posted it. Hello Maria Jack @2016mariaJack! For all the recent talk about Twitter bots, this seems like the most obvious bot ever.
We even have someone (ab)using two open-redirects in both Yahoo and Bing.
https://r.search.yahoo.com/cbclk ... RU=https%3a%2f%2fwww.bing.com%2faclick%3fld%3de8AoOppr-Kj72U0nyFE5h8ITVUCU ... https://www.bing.com/aclick? ... u=aHR0cHMlM2ElMmYlMm... (base64) ... www.skanskabyggvaror.seHmm. A Swedish company. I really wonder how they ended up at the end of this 18-step redirection chain...
Youtube
Some of the redirects go to YouTube videos. All of them have already been removed, good job YouTube! The content was mostly Elon Musk and Crypto scams.
Search engines
Some of the chains end up with search queries on different search engines. For example, "despicable me movies" on Bing:
https://www.bing.com/search?q=despicable%20me%20movies&PC=ATMS&FORM=MSMW01&PTAG=ATMS0100SW17
Some might be related to malware, like:
book torrent,
4k music downloader for pc,
3733 free mp3 downloads,
iphone 6 icloud unlock free.
The Soviet Union
I was surprised to see the Soviet Union actively participating in these graphs!
Apparently tulun.su (with the Soviet .su TLD)
is pushing casino spam together with its graph siblings like datcel.ru, pronk.ru, and zona-win.ru.
From this graph:
log-200k-req-home-normal.gv.pdf.
Crawling
Generating these graphs is tricky because these websites, and the introducer
the-best-cams.life in particular, have very good fingerprinting and bot detection.
Let's take a look at some levels of bot detection and then finally how to "bypass" it.
curl. If we run the following we do not get any redirects and just some dating app ads. Here the bot detection is done server-side.
curl https://the-best-cams.life//?u=bt1k60t&o=xqt63qn&t=cid:7120&cid=7120-0-20221202141033a7543d0a4curl + headers. Ok sure, standard curl is easy to detect, what about with headers and all?
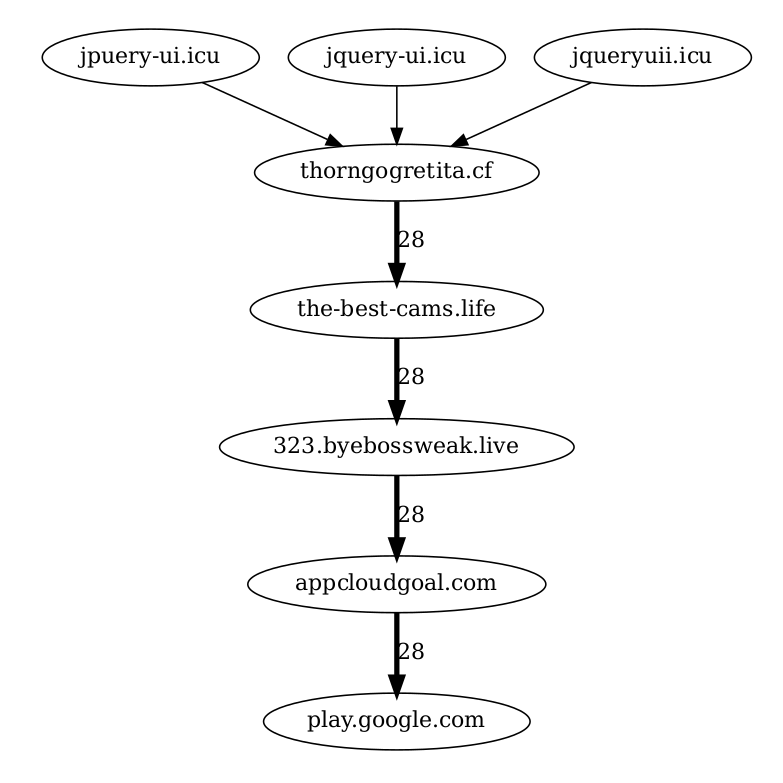
curl 'https://the-best-cams.life//?u=bt1k60t&o=xqt63qn&t=cid:7120&cid=7120-0-20221202141033a7543d0a4' -H 'User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:107.0) Gecko/20100101 Firefox/107.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8' -H 'Accept-Language: en-US,en;q=0.5' -H 'Accept-Encoding: gzip, deflate, br' -H 'DNT: 1' -H 'Connection: keep-alive' -H 'Upgrade-Insecure-Requests: 1' -H 'Sec-Fetch-Dest: document' -H 'Sec-Fetch-Mode: navigate' -H 'Sec-Fetch-Site: same-origin' -H 'Sec-Fetch-User: ?1' -H 'Pragma: no-cache' -H 'Cache-Control: no-cache'Selenium. Instead of trying to deobfuscate JavaScript we can use run a full browser using selenium. In this case, as shown by the graph below, all requests go to the same place. For some strange reason is the official TikTok android app https://play.google.com/store/apps/details?id=com.zhiliaoapp.musically&hl=en&gl=US.
Moreover, we can compare the vectors generated by the fingerprinting script to see exactly how it detects we are using selenium. The first value that differs between running my normal browser and the same browser in Selenium is A11, which checks 'webdriver' in navigator.webdriver. Perhaps something like selenium-stealth could solve this.
No bot (almost). Instead of fighting the spammers on their home court, I opted for going up one abstraction level. That is, instead of changing the browser, I would use a real Chrome browser but use a custom extension to drive it. You can download my extension from GitHub: ScanSpam. The extension is based on Traffic Analyser with my additions to continuously extract the requests, fetch the spam websites and handle arbitrary amounts of tabs in parallel. Below is a short video of the execution of the extension.
Conclusion
These networks are vaster than I could have imagined and more work is needed to understand them in more detail.
We see advanced methods for fingerprinting, ensuring that automated solutions such as Selenium do not see the entire network.
We also see multiple redirection methods, using open redirects in search engines and social networks such as Twitter.
This study only focuses on one entry point (the fake jQuery domains). If you know any other website pointing to, for example, the-best-cams.life please let me know.
Fun read! ^^