
TS-Streams and Exercising
A few weeks ago my girlfriend showed me that the gym she goes to had started to upload instructional videos online. We decide to try one and I have to say, the videos were surprisingly good. However, there was one problem, our internet connection is quite unstable which resulted in the player constantly lagging as it tried to change the quality of video. To fix this I set out on quest to find a way to "buffer" the whole video before watching it.
I started with the basic techniques, searching the source code for video files, analyzing variables sent to video player, etc. Sadly, I didn't find anything interesting. I even tested some browser extensions for fetching video but none of them worked either. At this point the next logical step would be to bite the bullet and fire up wireshark, even though it's a nuisance to use with SSL traffic. However, just before I started wireshark I realised that Chrome actually has a built in network analyser and to my delight it worked great!
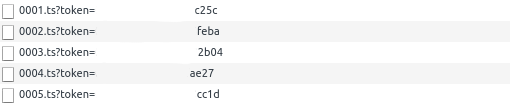
As the image shows, the video is split up into sequential chunks of data, 0001.ts, 0002.ts, etc. After doing some reasearch I found out that the standard they used is called MPEG transport stream[1] and to get the whole video you simply had to concatenate all the ts-files. The next challenge was to download all the ts-files, which would be simple if it weren't for the seemingly random tokens. Digging deeper into to the network logs I finally found how it all fits together.
The browser starts by requesting a playlist file, e.g playlist.m3u8. This list contains information about the available chunklists. Each chunklist will have different attributes like resolution and bandwidth.
#RESOLUTION=1280x720
Chunklist_720p.m3u8?token=89234
#RESOLUTION=854x480
Chunklist_480p.m3u8?token=19432
0000.ts?token=91234
0001.ts?token=55342
0002.ts?token=66345
0003.ts?token=11114
With all this sorted out it was time to write the client program, the source code for the client can be found at github. The idea was to write one general script for downloading videos and one specific script to fetch the playlist from the gym's website.
The general script, aptly named dlts.py, is quite straightforward. It takes a playlist url as input and then prints the full url of each ts-file. By default dlts.py will pick the chunklist with highest resolution but alternative behavior can be specified through arguments.
The gym script seemed like a bigger challenge but they actually had a big JSON file[2] with all the videos. Since this file is public it can't contain the url to the full video, this is where it gets tricky. Instead of the video url we have to visit the "product page", from there we can continue to the "watch page", to finally get the player.js file that contains the playlist url. I should clarify that you still need a valid membership to use the script.
From playlist to full video can be achieved by running:
python dlts.py | wget -i - ; cat *.ts > full.ts
Now all that is left is to actually watch the videos...
Notes
- MPEG Transport Stream https://en.wikipedia.org/wiki/MPEG_transport_stream
- Public JSON file https://www.sats.se/satselixia/webapi/filteredproducts/sv/21155/0 (If you get an error, try using wget or 'save link as')