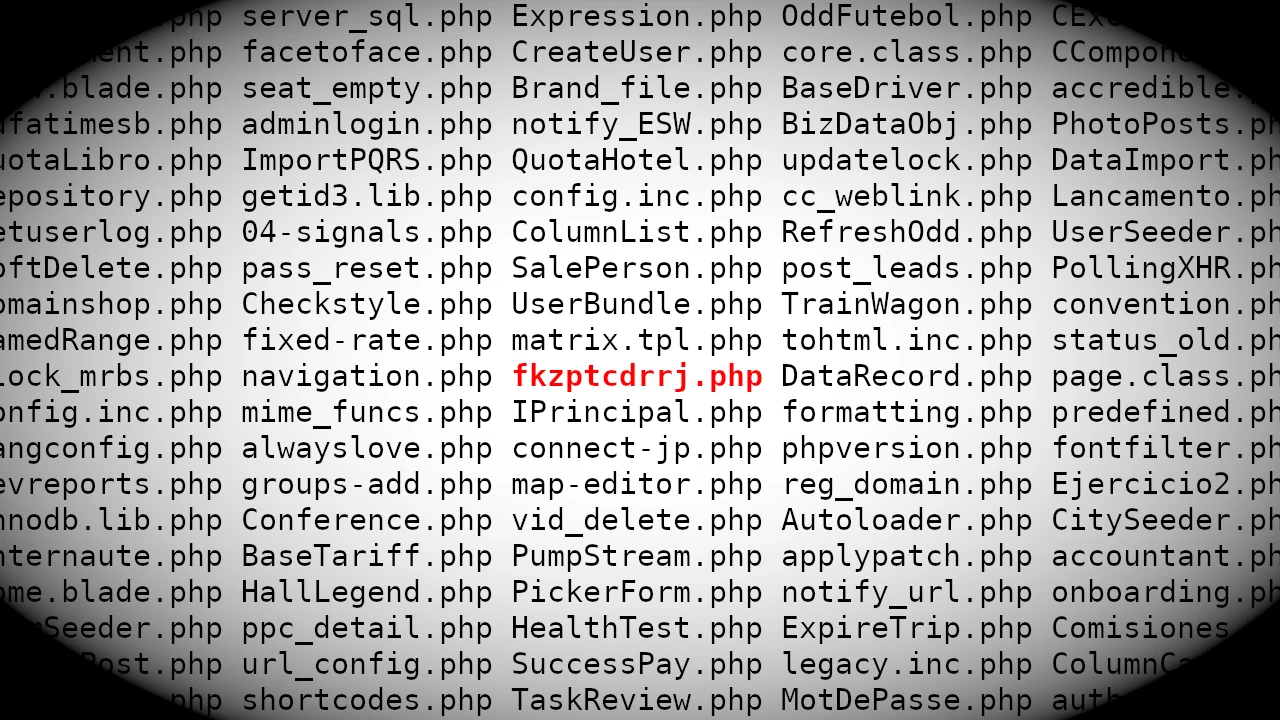
Searching for Random
As I was "casually" surfing the web I stumbled upon some PHP files with random names. It turns out that these files are backdoors created by a hacking tool, which might warrant a post on its own later. The problem is that you can't really search for random data in a similar fashion as you can do with Google Dorks for specific files. So given a bunch of files, how would you find the ones with random names? In this post, I'll outline a statistical approach (#AI, #MachineLearning, #BigData, ...) I managed to use with some success to find multiple active and useable backdoors online. That being said, it's only a first step and far from perfect, any input on possible improvements is appreciated!
Motivating example
To shine some more light on what I mean, here is an example:
Which of these five files have a random name?
- readertest.php
- fkzptcdrrj.php
- timeserver.php
- datatables.php
- fileserver.php
For anyone that knows English, this is pretty obvious, it's fkzptcdrrj.php.
While it's easy to tell in this case, how would you program a general solution for finding this file?
Specification
In the specific case of this malware, there are some things we know. The filename, excluding extension, is ten characters long and only lowercase letters. This is based on observations, I still haven't found the exact generating function for the names.
Method
My first idea was to try some machine learning solution to detect English but I didn't like that solution. Firstly, it would fail for non-English names like "configuraracceso.php", "MotDePasse.php", etc. Secondly, it might also break for names with special characters like "edit_user.php", "wp-login.php", etc.
Since my wife is a librarian and a professional in data retrieval, I started by asking her. Understandably, she was a bit stumped at my request to find random names. However, before soon she recommended looking for names with "unlikely patterns".
Happily, I have created my own database with lots of file names that I use to uncover these unlikely patterns. The idea was to use this to create a Markov Chain with transition probabilities between characters in the names. Then finally, for each name, calculate the probability for the corresponding path in the chain. The names with the lowest probability are the "unlikely patterns".
To generate the Markov Chain I used approximately 16,000 unique file names of variable length converted to lowercase.
Example
If we have the files "abc", "aaa", and "aac" we construct the following chain. We start with "abc" where we have one "a → b" transition and one "b → c" transition, then "aaa" with two "a → a" transition and finally "aac" with one "a → a" and one "a → c" transition. Now, for "a" there is a 1/5 chance the next character is "b", 3/5 it is "a" and a 1/5 that it is "c".
Results
Starting with the Markov Chain, the transitions seem to make sense. "f → i" is very popular at about 18% (any file name with "file" in the name will add to this), while "f → v" is very unlikely at 0.02%. Below is the Markov Chain for the likely name "fileserver".
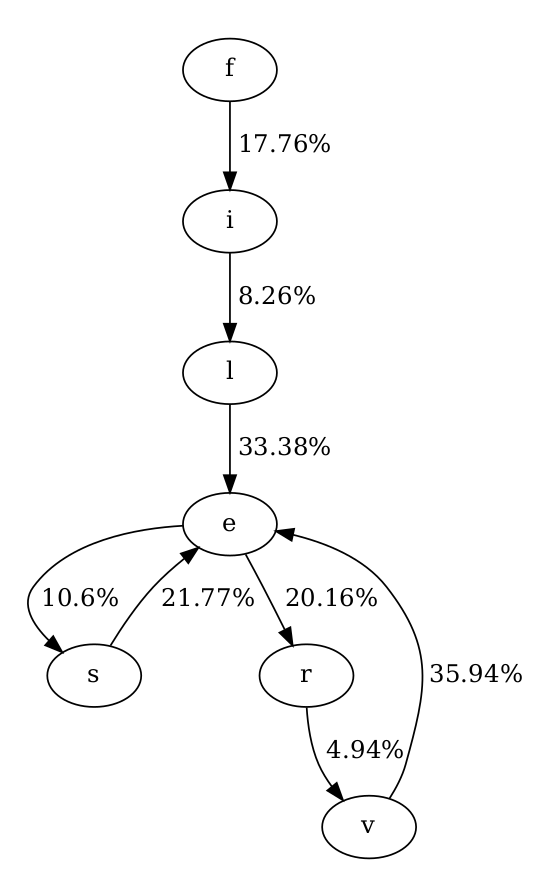
The top five most "likely" ten letter names results were:
- fileserver.php (8.2e-08)
- datatables.php (7.1e-08),
- controller.php (7.0e-08),
- icontainer.php (1.9e-08),
- convention.php (1.8e-08).
And for the key results, the most "unlikely" names (slightly changed to preserve anonymity for victims):
- u5xvnsnvdn.php (1.42e-24)
- wp-dk1ugc4.php (4.3e-21)
- fkzptcdrrj.php (1.23e-20)
- wp-z0czikm.php (1.6e-19)
- wp-05qvpwb.php (2.4e-19)
I am very happy with these results! All top five results are from hacked servers. fkzptcdrrj.php was executable allowing for RCE. Actually, 1,2,4, and 5 are all from the same hacked server.
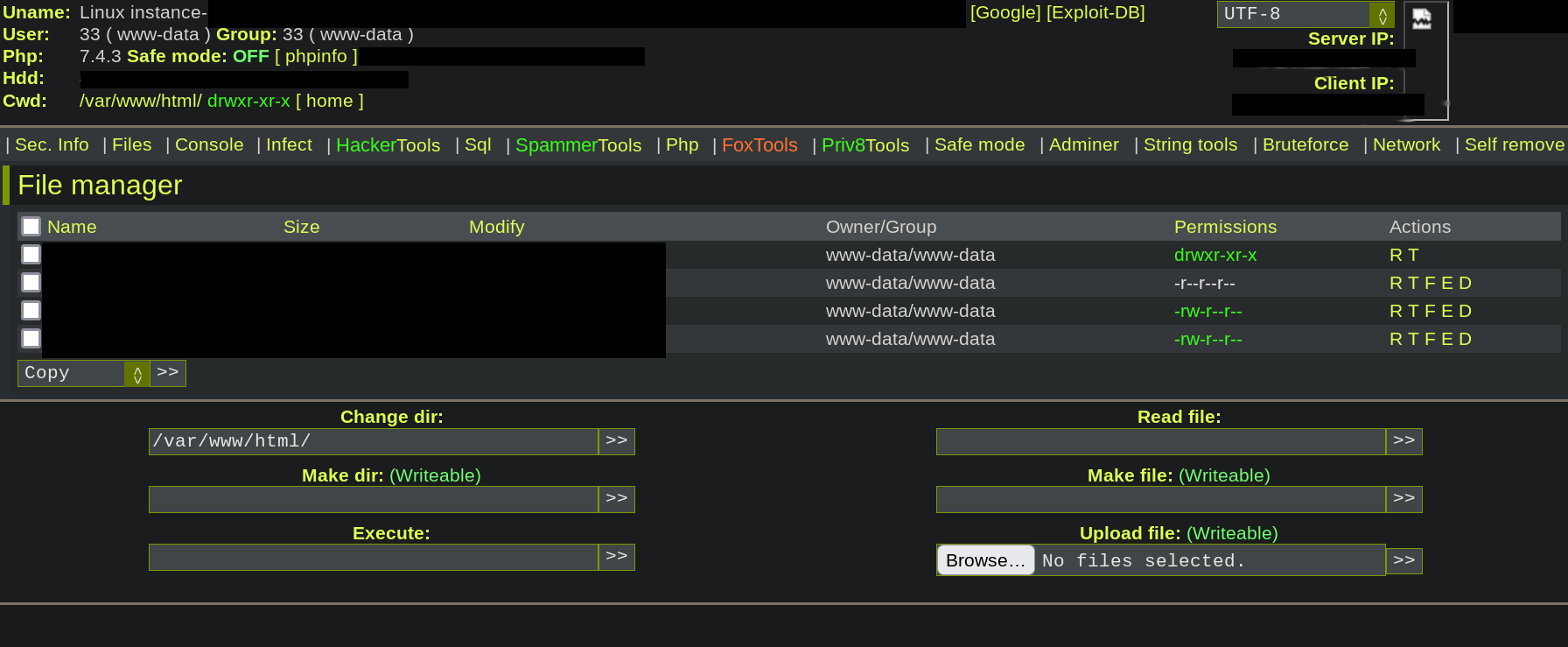
The seventh most unlikely pattern was an active web shell from the same malware authors that anyone could use on the infected server, as shown in the figure below.
Discussion
While I think these results were surprisingly good I'm sure there is much room for improvement. Even continuing on the Markov Chain model there are many parameters. Should everything be converted to lowercase? Should only unique names be used? If the target length is 10, should only names of this length be used?
Looking at more than the top 5 results, there are quite a lot of false positives (non-random names) like "logoff_wtd", "notify_vtm", "bookflight". The first two are combinations of words and other data. "bookflight" is interesting as it is a combination of two normal English words, but the "k → f" transition is quite rare (1%). Some names arguably seem random, like "esp8266h2o", unless you know that "ESP8266" is a microchip. So perhaps including some word lists or knowledge databases could help eliminate false positives.
Almost eveyone I've told about this to have mentioned ENTROPY! "Just calculate the entropy", "find the name with highest entropy", etc. But this is really not straight forward. Sometimes a simplified version is used for passwords where entropy can be calculated as E = L * log2(R), where L is the length and R the size of the character set. This doesn't really help us in deciding if "admin" or "fkzpt" has the highest entropy, as the have the same length and possible same character set [a-z]. I believe the core problem is that we need to know the distribution of file names before entropy can be applied. Please let me know if you have a good idea on this track!
Conclusion
Markov chains are pretty good at finding probable patterns and consequently also non-patterns or randomness. Furthermore, multiple of the random files I found were indeed malicious with some even providing RCE on the infected servers.
Write your comment!
Comments
Awesome idea AM! :)
For the total probability of a filename, I'm simply taking the product of each ngram in the filename divided by the total weighted ngrams in the dataset. This seems to work but maybe there is a more correct method to do it?
Looking at the bigrams the results are very similar with pretty much the same top lists for both common and uncommon. I guess this makes sense as bigrams and transition probabilities between individual characters are similar. The most common bigrams are "er" (423/13140) and "on" (284/13140). Indeed you are correct that "ad" (86/13140) is much more common than "fk" (1/13140), nice!
Trigrams also give similar results but perhaps a bit more false positives. For example, "subscriber" is the third most unlikely result. Most common trigrams are "ion", "con", and "tio", which makes sense too.
In practice, it would probably be useful to complement/filter the results w.r.t. to popular dictionaries.
Not if you consider letters separately, but you could split the word into n-grams (2- or 3- grams could be enough), and then compare by their entropy instead. "ad" should be a much more common 2-gram than "fk" in most popular languages.